
Every startup founder today faces this question. McKinsey reports that 87% of businesses believe AI will give them a competitive advantage, but only 23% have successfully implemented AI features in their products. The gap? The overwhelming complexity of AI infrastructure.
Traditional AI implementation requires specialized vector databases, embedding pipelines, model serving infrastructure, and complex data synchronization between "normal" data and AI data. The result: AI projects take 6-12 months longer than expected and cost 3x more than budgeted.
But what if adding sophisticated AI to your startup was as simple as adding user authentication or file storage?
Supabase is revolutionizing AI development for startups by providing AI-ready infrastructure out of the box. With built-in vector database support, seamless AI API integration, and unified data management, you can build intelligent applications without the traditional complexity or cost barriers.
The AI opportunity is massive. The implementation doesn't have to be.The AI Implementation Nightmare Facing Startups
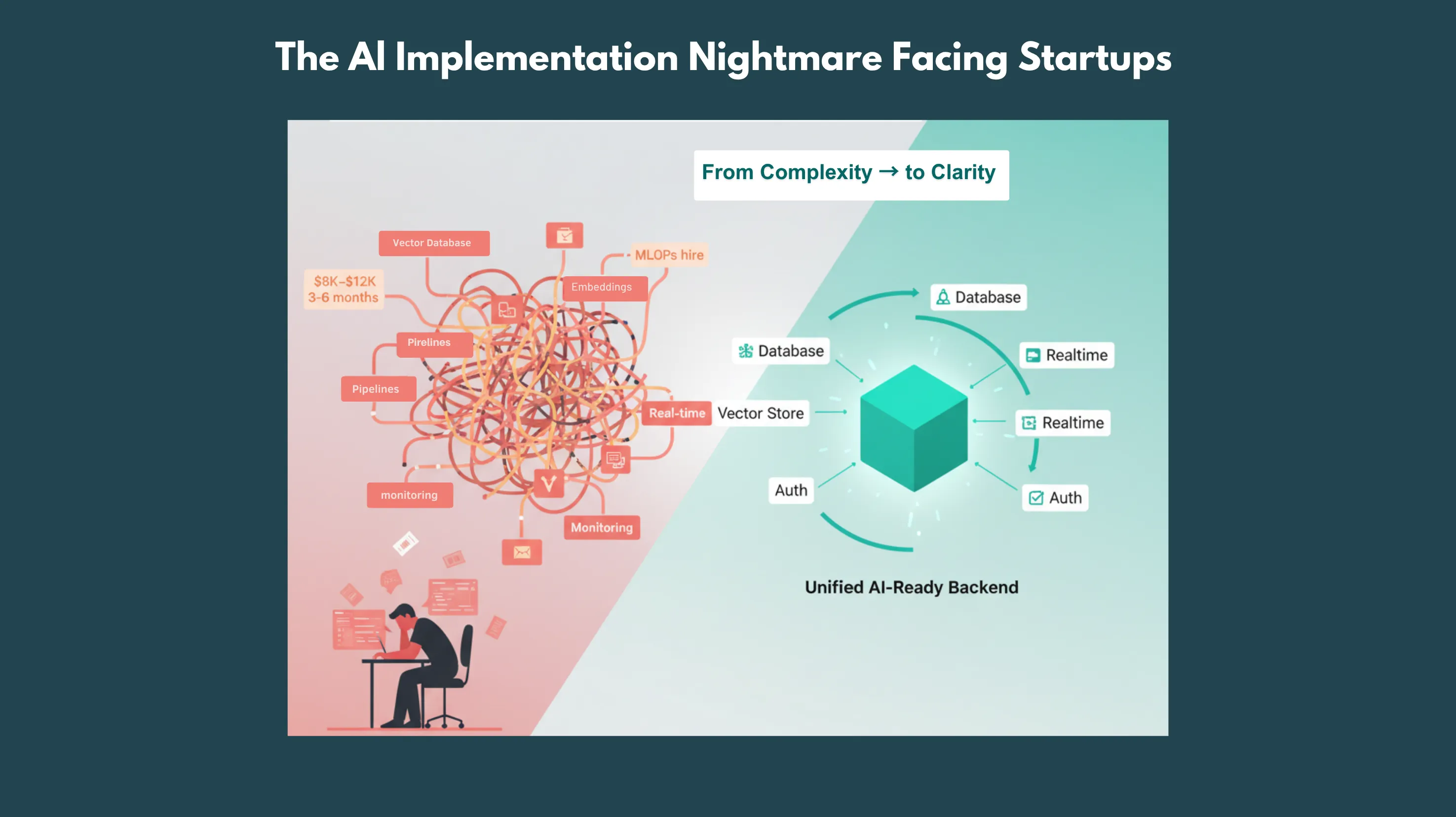
Picture this: Your SaaS platform has found product-market fit with 5,000 users. Customers are asking for AI-powered features, intelligent recommendations, automated insights, smart search. You know this could 10x your value proposition, but the technical requirements feel overwhelming.
1. Traditional AI Infrastructure Requirements:
- Vector database: 2-3 weeks ($8,000-$12,000 in developer time)
- Embedding generation: 2-4 weeks ($8,000-$16,000)
- Data pipeline: 1-2 weeks ($4,000-$8,000)
- Model serving: 3-4 weeks ($12,000-$16,000)
- Real-time processing: 2-3 weeks ($8,000-$12,000)
- Monitoring and analytics: 2-3 weeks ($8,000-$12,000)
2. Development Complexity:
Beyond development costs, traditional setups require multiple service subscriptions:
- 3-6 months: Additional development time for AI infrastructure
- $50K-$150K: Extra development costs for AI-specific architecture
- 2-3 specialized hires: AI engineers, MLOps specialists, data engineers
- Ongoing maintenance: 20-30% of development time managing AI infrastructure
- The result?: Most startups either abandon AI plans or over-engineer solutions that drain resources and slow product development.
3. RealStartup AI HorrorStories
- E-commerce Startup: Spent 8 months building a recommendation engine with separate vector database, spent $200K, only to achieve 12% improvement in click-through rates. Traditional collaborative filtering would have delivered 80% of the benefit in 2 weeks.
- Content Platform: Built complex embedding pipeline for semantic search, took 6 months and required 3 specialized engineers. Users actually preferred simple keyword search with better UX.
- Customer Support SaaS: Implemented chatbot with RAG (Retrieval-Augmented Generation), spent $150K on infrastructure. Discovered customers wanted better human handoff, not more AI responses.
- The pattern is clear: Complex AI infrastructure often distracts from solving real user problems.
Supabase: AI Infrastructure That Just Works
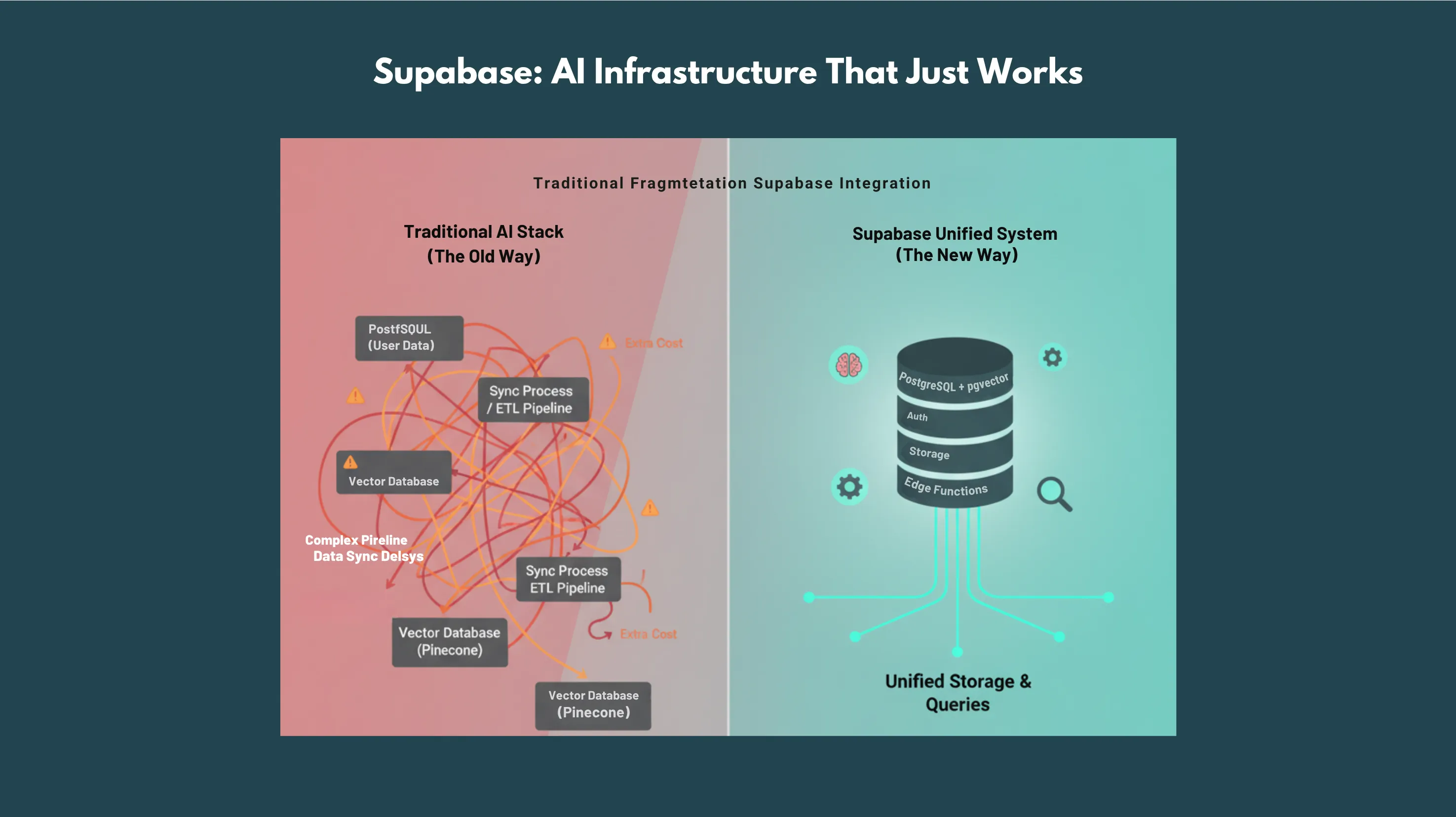
Supabase fundamentally changes the AI development equation by providing sophisticated AI capabilities through the same simple interface you already use for your application data.
1. The Revolutionary Integration:pgvector
At the heart of Supabase's AI capabilities is pgvector, a PostgreSQL extension that turns your existing database into a powerful vector database. This isn't just a nice-to-have feature; it's a game-changing architectural advantage.
| Traditional Approach | Supabase Approach |
|---|---|
|
|
Real-World Impact: This free tier can easily support 1,000-5,000 monthly active users for most MVP applications, more than enough for initial market validation and investor demos.
- No data synchronization: User data and AI embeddings live in the same database
- ACID compliance: AI data integrity guaranteed with traditional database transactions
- Familiar tooling: Use SQL to query both traditional and vector data
- Real-time updates: AI data updates automatically when user data changes
- Cost efficiency: One database instead of multiple specialized services
2. Built-in AI CapabilitiesThat Actually Matter
Vector Storage and Similarity Search:
-- Store embeddings alongside your regular data
CREATE TABLE documents (
id bigint PRIMARY KEY,
content text,
embedding vector(1536), -- OpenAI embedding size
user_id bigint REFERENCES users(id)
);
-- Find similar content with simple SQL
SELECT content, 1 - (embedding <=> query_embedding) AS similarity
FROM documents
ORDER BY embedding <=> query_embedding
LIMIT 10;
- Database triggers: Automatically generate embeddings when content changes
- Edge functions: Run AI processing close to your users
- Webhook integration: Connect to any AI service or model
- Background jobs: Handle expensive AI operations asynchronously
- Usage tracking: Monitor AI feature adoption and performance
- Cost analysis: Track AI API usage and optimize spending
- Performance metrics: Measure AI feature impact on user engagement
- A/B testing: Test different AI approaches with built-in experimentation
Real-World AI Success Stories: From Conceptto Production
CaseStudy 1: EdTechPlatform -PersonalizedLearning Recommendations
Background: An online learning platform with 25,000 students wanted to implement personalized course recommendations to improve completion rates and student satisfaction.
Traditional AI Approach Would Have Required:
- Vector database setup: Pinecone subscription and integration ($300/month)
- Embedding pipeline: Custom ETL to sync course and user data
- Recommendation engine: Separate microservice for similarity calculations
- Data consistency: Complex sync between user database and recommendation system
- Timeline time: 4-6 months of development
- Cost time: $80K-$120K for implementation
Supabase AI Implementation:
-- Store course embeddings alongside course data
ALTER TABLE courses ADD COLUMN embedding vector(1536);
-- Generate embeddings for user learning preferences
ALTER TABLE user_preferences ADD COLUMN learning_style_embedding vector(1536);
-- Real-time recommendations with simple SQL
CREATE OR REPLACE FUNCTION get_course_recommendations(user_id bigint)
RETURNS TABLE(course_id bigint, title text, similarity_score float)
AS $$
BEGIN
RETURN QUERY
SELECT
c.id,
c.title,
1 - (c.embedding <=> up.learning_style_embedding) AS score
FROM courses c, user_preferences up
WHERE up.user_id = get_course_recommendations.user_id
ORDER BY c.embedding <=> up.learning_style_embedding
LIMIT 10;
END;
$$ LANGUAGE plpgsql;
Results
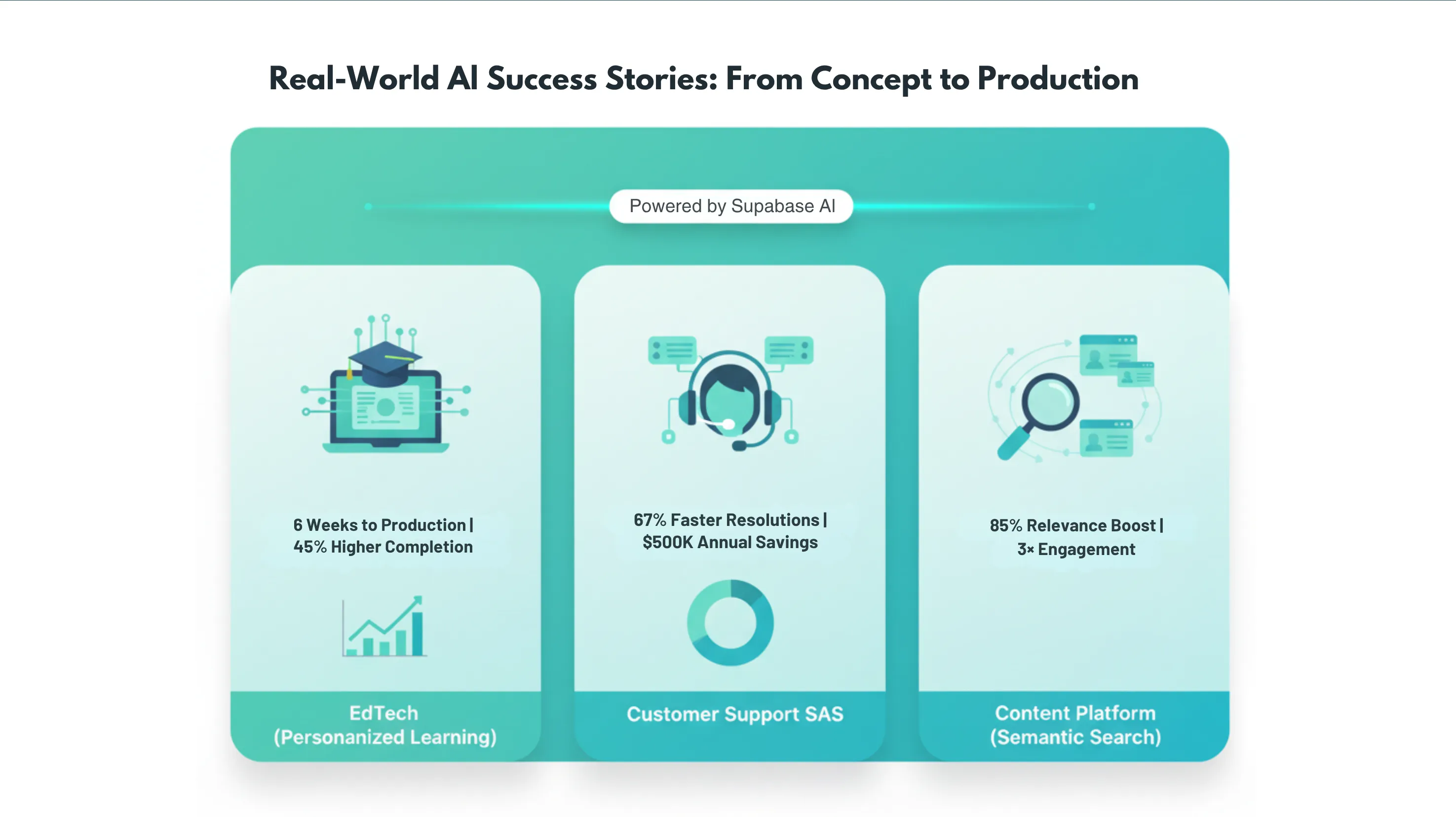
- 6 weeks: From concept to production deployment
- 45% improvement: In course completion rates
- 3x higher engagement: Students spent more time on recommended courses
- $15K total cost: 80% savings compared to traditional approach
- Real-time updates: Recommendations improve as students learn
Founder Quote:"We thought AI recommendations would take months and cost a fortune. With Supabase, we had working recommendations in 6 weeks, and our completion rates went through the roof."
CaseStudy2: CustomerSupportSaaS- IntelligentTicket Routing
Background: A customer support platform handling 50,000+ tickets monthly needed intelligent routing to match tickets with the best-qualified support agents.
AI Requirements:- Semantic understanding: Route tickets based on content meaning, not just keywords
- Agent expertise modeling: Learn which agents handle which types of issues best
- Real-time processing: Route tickets immediately upon creation
- Continuous learning: Improve routing based on resolution outcomes
1. Ticket Embedding and Storage:
-- Enhanced tickets table with AI capabilities
CREATE TABLE support_tickets (
id bigint PRIMARY KEY,
subject text,
content text,
content_embedding vector(1536),
priority_level text,
customer_id bigint,
assigned_agent_id bigint,
status text,
created_at timestamp DEFAULT now()
);
-- Agent expertise profiles
CREATE TABLE agent_expertise (
agent_id bigint REFERENCES agents(id),
expertise_embedding vector(1536),
success_rate float,
average_resolution_time interval
);
2. Intelligent Routing Function:
CREATE OR REPLACE FUNCTION route_ticket_intelligently(ticket_id bigint)
RETURNS bigint AS $$
DECLARE
ticket_embedding vector(1536);
best_agent_id bigint;
BEGIN
-- Get the ticket embedding
SELECT content_embedding INTO ticket_embedding
FROM support_tickets WHERE id = ticket_id;
-- Find best matching agent
SELECT agent_id INTO best_agent_id
FROM agent_expertise
ORDER BY expertise_embedding <=> ticket_embedding
LIMIT 1;
-- Update ticket assignment
UPDATE support_tickets
SET assigned_agent_id = best_agent_id
WHERE id = ticket_id;
RETURN best_agent_id;
END;
$$ LANGUAGE plpgsql;
3. Continuous Learning Pipeline:
-- Update agent expertise based on resolved tickets
CREATE OR REPLACE FUNCTION update_agent_expertise()
RETURNS void AS $$
BEGIN
-- Recalculate agent expertise embeddings based on successful resolutions
WITH successful_tickets AS (
SELECT
assigned_agent_id,
AVG(content_embedding) AS avg_embedding,
COUNT(*) AS resolution_count,
AVG(EXTRACT(EPOCH FROM (resolved_at - created_at)) / 3600) AS avg_hours
FROM support_tickets
WHERE status = 'resolved'
AND customer_satisfaction >= 4
GROUP BY assigned_agent_id
)
UPDATE agent_expertise
SET
expertise_embedding = st.avg_embedding,
success_rate = st.resolution_count::float / (
SELECT COUNT(*) FROM support_tickets
WHERE assigned_agent_id = st.assigned_agent_id
),
average_resolution_time = make_interval(hours => st.avg_hours)
FROM successful_tickets st
WHERE agent_expertise.agent_id = st.assigned_agent_id;
END;
$$ LANGUAGE plpgsql;
Business Impact:
- 67% faster resolution: Tickets routed to the right expert immediately
- 40% higher satisfaction: Customers get help from specialists
- 30% agent productivity increase: Agents work on issues matching their expertise
- $500K annual savings: Reduced escalations and faster resolutions
- 8-week implementation: From concept to full production deployment
Case Study3: Content CreationPlatform - AI-Powered Content Discovery
Background: A content creation platform with 100,000+ articles needed semantic search and content recommendations to help users discover relevant information.
Challenge: Traditional keyword search returned irrelevant results, and users couldn't find related content effectively.
Supabase AI Solution:
1. Content Embedding Storage:
-- Enhanced content table with semantic search capabilities
CREATE TABLE articles (
id bigint PRIMARY KEY,
title text,
content text,
summary text,
title_embedding vector(1536),
content_embedding vector(1536),
author_id bigint,
published_at timestamp,
view_count bigint DEFAULT 0,
engagement_score float DEFAULT 0
);
-- Content similarity index for fast searches
CREATE INDEX ON articles USING ivfflat (content_embedding vector_cosine_ops);
2. Semantic Search Function:
CREATE OR REPLACE FUNCTION semantic_search(
query_text text,
search_limit int DEFAULT 20,
similarity_threshold float DEFAULT 0.7
)
RETURNS TABLE(
article_id bigint,
title text,
summary text,
similarity_score float,
relevance_rank int
) AS $$
DECLARE
query_embedding vector(1536);
BEGIN
-- Generate embedding for search query (using Edge Function)
SELECT embedding INTO query_embedding
FROM generate_embedding(query_text);
RETURN QUERY
SELECT
a.id,
a.title,
a.summary,
1 - (a.content_embedding <=> query_embedding) AS similarity_score,
ROW_NUMBER() OVER (ORDER BY a.content_embedding <=> query_embedding) AS relevance_rank
FROM articles a
WHERE 1 - (a.content_embedding <=> query_embedding) > similarity_threshold
ORDER BY a.content_embedding <=> query_embedding
LIMIT search_limit;
END;
$$ LANGUAGE plpgsql;
3. Related Content Recommendations:
CREATE OR REPLACE FUNCTION get_related_articles(
article_id bigint,
limit_count int DEFAULT 5
)
RETURNS TABLE(
related_id bigint,
title text,
similarity_score float
) AS $$
BEGIN
RETURN QUERY
SELECT
a2.id,
a2.title,
1 - (a1.content_embedding <=> a2.content_embedding) AS similarity
FROM articles a1, articles a2
WHERE a1.id = article_id
AND a2.id != article_id
ORDER BY a1.content_embedding <=> a2.content_embedding
LIMIT limit_count;
END;
$$ LANGUAGE plpgsql;
Performance Results:
- 85% improvement: In search result relevance scores
- 3x higher engagement: Users spent more time reading recommended content
- 50% increase: In content discovery and cross-article navigation
- Sub-100ms response: Fast semantic search across 100K+ articles
- Zero infrastructure overhead: No separate search service required
The Technical Deep Dive: How Supabase Makes AI Simple
1. Vector Database CapabilitiesStorage and Indexing:
-- Different vector sizes for different AI models
CREATE TABLE embeddings_example (
id bigint PRIMARY KEY,
openai_embedding vector(1536), -- OpenAI text-embedding-ada-002
cohere_embedding vector(4096), -- Cohere embeddings
sentence_transformer vector(768), -- Sentence transformers
custom_embedding vector(512) -- Custom model embeddings
);
-- Optimized indexes for different similarity metrics
CREATE INDEX ON embeddings_example USING ivfflat (openai_embedding vector_cosine_ops);
CREATE INDEX ON embeddings_example USING ivfflat (openai_embedding vector_l2_ops);
CREATE INDEX ON embeddings_example USING ivfflat (openai_embedding vector_ip_ops);
Similarity Search Operations:
-- Cosine similarity (most common for text embeddings)
SELECT * FROM documents
ORDER BY embedding <=> query_embedding
LIMIT 10;
-- Euclidean distance
SELECT * FROM documents
ORDER BY embedding <-> query_embedding
LIMIT 10;
-- Inner product
SELECT * FROM documents
ORDER BY embedding <#> query_embedding
LIMIT 10;
-- Combined with traditional filters
SELECT * FROM documents
WHERE user_id = $1
AND created_at > $2
ORDER BY embedding <=> query_embedding
LIMIT 10;
Edge Functions for AI Processing:
// Supabase Edge Function for embedding generation
import { serve } from "https://deno.land/std@0.168.0/http/server.ts"
import { createClient } from "https://esm.sh/@supabase/supabase-js@2"
serve(async (req) => {
const { text, table, id } = await req.json()
// Generate embedding using OpenAI
const embeddingResponse = await fetch("https://api.openai.com/v1/embeddings", {
method: "POST",
headers: {
"Authorization": "Bearer $"{Deno.env.get(
"OPENAI__API__KEY"
)}",
"Content-Type": "application/json",
},
body: JSON.stringify({
input: text,
model: "text-embedding-ada-002",
}),
})
const { data } = await embeddingResponse.json()
const embedding = data[0].embedding
// Store embedding in Supabase
const supabase = createClient(
Deno.env.get("SUPABASE_URL")!,
Deno.env.get("SUPABASE_SERVICE_ROLE_KEY")!
)
const { error } = await supabase
.from(table)
.update({ embedding })
.eq("id", id)
return new Response(JSON.stringify({ success: !error }), {
headers: { "Content-Type": "application/json" },
})
})Real-time Embedding Updates:
-- Database trigger to automatically generate embeddings
CREATE OR REPLACE FUNCTION generate_embedding_trigger()
RETURNS trigger AS $$
BEGIN
-- Call Edge Function to generate embedding when content changes
PERFORM
net.http_post(
url := 'https://your-project.supabase.co/functions/v1/generate-embedding',
headers := '{"Content-Type": "application/json", "Authorization": "Bearer ' || current_setting('app.service_role_key') || '"}'::jsonb,
body := jsonb_build_object(
'text', NEW.content,
'table', TG_TABLE_NAME,
'id', NEW.id
)::jsonb
);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
-- Apply trigger to automatically update embeddings
CREATE TRIGGER update_content_embedding
AFTER INSERT OR UPDATE OF content ON articles
FOR EACH ROW
EXECUTE FUNCTION generate_embedding_trigger();Advanced AI Use Cases
1. Multi-modal Embeddings:
-- Store different types of embeddings for rich content
CREATE TABLE multimedia_content (
id BIGINT PRIMARY KEY,
title TEXT,
description TEXT,
image_url TEXT,
video_url TEXT,
text_embedding VECTOR(1536),
image_embedding VECTOR(512),
combined_embedding VECTOR(2048)
);
-- Search across multiple modalities
CREATE OR REPLACE FUNCTION multimodal_search(
query_text TEXT DEFAULT NULL,
query_image_embedding VECTOR(512) DEFAULT NULL
)
RETURNS TABLE (content_id BIGINT, relevance_score FLOAT) AS $$
BEGIN
IF query_text IS NOT NULL AND query_image_embedding IS NOT NULL THEN
-- Combined text and image search
RETURN QUERY
SELECT
id,
(0.7 * (1 - (text_embedding <=> get_text_embedding(query_text)))) +
(0.3 * (1 - (image_embedding <=> query_image_embedding))) AS score
FROM multimedia_content
ORDER BY score DESC;
ELSIF query_text IS NOT NULL THEN
-- Text-only search
RETURN QUERY
SELECT
id,
1 - (text_embedding <=> get_text_embedding(query_text)) AS score
FROM multimedia_content
ORDER BY text_embedding <=> get_text_embedding(query_text);
END IF;
END;
$$ LANGUAGE plpgsql;2. Hierarchical Embeddings:
-- Support for document chunks and full document embeddings
CREATE TABLE document_hierarchy (
id BIGINT PRIMARY KEY,
document_id BIGINT,
chunk_id BIGINT,
content TEXT,
chunk_embedding VECTOR(1536),
document_embedding VECTOR(1536),
chunk_order INT,
parent_chunk_id BIGINT
);
-- Hierarchical search with context
CREATE OR REPLACE FUNCTION hierarchical_search(query_text TEXT)
RETURNS TABLE (
document_id BIGINT,
best_chunk_id BIGINT,
context_chunks JSONB,
relevance_score FLOAT
) AS $$
BEGIN
RETURN QUERY
WITH chunk_matches AS (
SELECT
dh.document_id,
dh.chunk_id,
dh.content,
dh.chunk_order,
1 - (dh.chunk_embedding <=> get_text_embedding(query_text)) AS score
FROM document_hierarchy dh
ORDER BY dh.chunk_embedding <=> get_text_embedding(query_text)
),
best_matches AS (
SELECT DISTINCT ON (document_id)
document_id,
chunk_id,
content,
chunk_order,
score
FROM chunk_matches
ORDER BY document_id, score DESC
)
SELECT
bm.document_id,
bm.chunk_id AS best_chunk_id,
(
SELECT jsonb_agg(
jsonb_build_object(
'chunk_id', dh2.chunk_id,
'content', dh2.content,
'order', dh2.chunk_order
)
ORDER BY dh2.chunk_order
)
FROM document_hierarchy dh2
WHERE dh2.document_id = bm.document_id
AND dh2.chunk_order BETWEEN bm.chunk_order - 2 AND bm.chunk_order + 2
) AS context_chunks,
bm.score AS relevance_score
FROM best_matches bm
ORDER BY bm.score DESC;
END;
$$ LANGUAGE plpgsql;Cost Analysis: AI on a Startup Budget
 Traditional AIInfrastructure Costs
Traditional AIInfrastructure Costs
Vector Database Services:
- Pinecone: $70-$500/month for production workloads
- Weaviate Cloud: $100-$400/month for managed service
- Chroma: Self-hosted infrastructure costs $200-$800/month
- Qdrant: $50-$300/month for cloud service
AI Model APIs
- OpenAI Embeddings: $0.0001 per 1K tokens (can add up quickly)
- Cohere Embeddings: $0.0001 per 1K tokens
- Anthropic Claude: $0.01-$0.06 per 1K tokens for reasoning
- Custom model hosting: $500-$2,000/month for dedicated inference
Development and Operations:
- AI Engineer: $150K-$220K annually
- MLOps Specialist: $130K-$200K annually
- Data Engineering: $120K-$180K annually
- Infrastructure Management: 20-30% of engineering time
Additional Services:
- Data Pipeline Tools: $100-$500/month
- Monitoring and Observability: $50-$200/month
- Model Versioning: $50-$150/month
- A/B Testing Platform: $100-$300/month
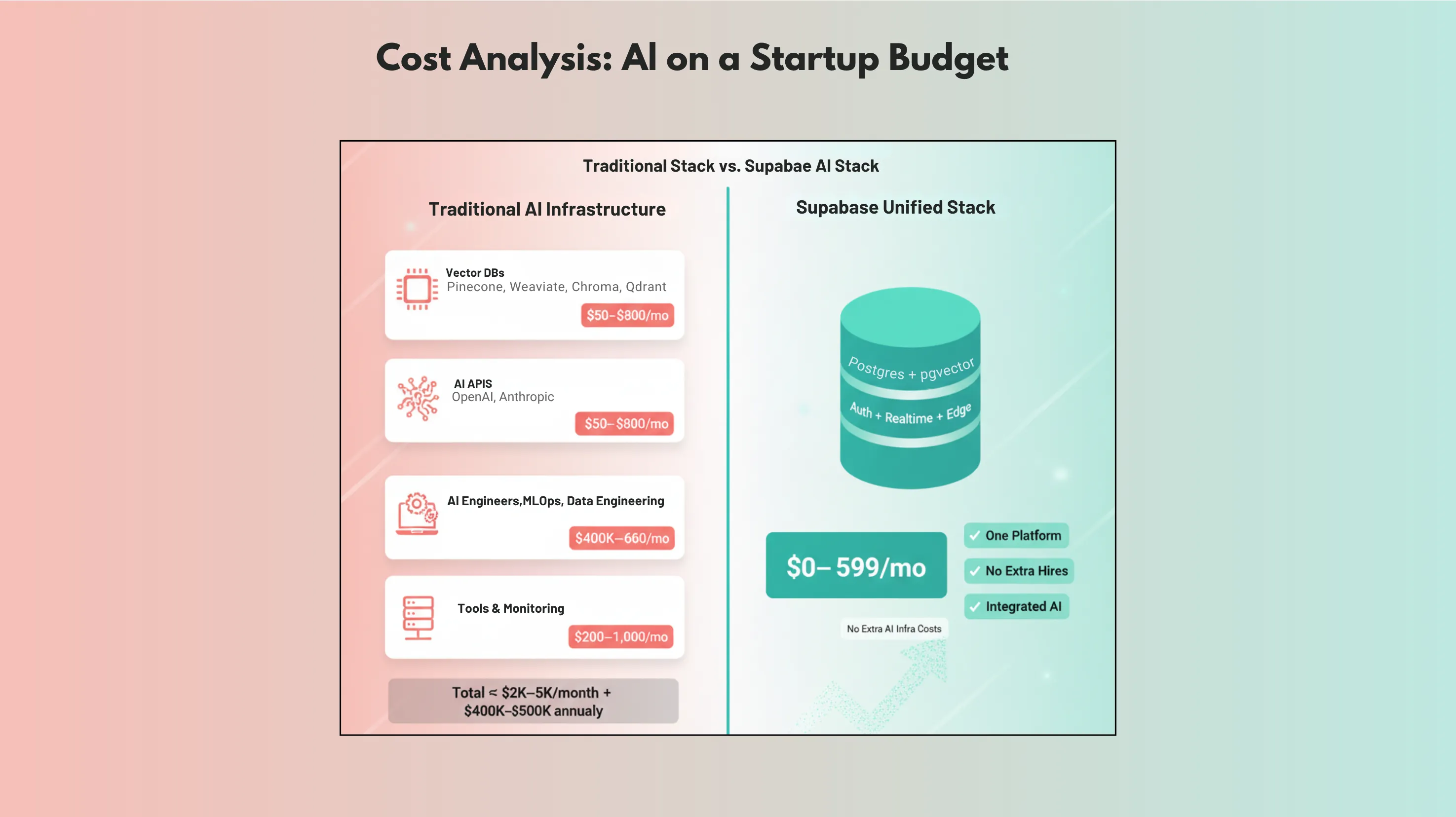
- Total Monthly Cost for Typical AI Startup: $2,000-$5,000/month + $400K-$600K annually in specialized talent
Supabase AIImplementation Costs
Platform Costs:
- Free Tier: Supports AI experimentation and small-scale deployment
- Pro Plan: $25/month includes vector storage and edge functions
- Team Plan: $599/month for production AI applications
- Enterprise: Custom pricing for large-scale AI workloads
AI API Costs (same as traditional):
- OpenAI Embeddings: $0.0001 per 1K tokens
- Other AI Services: Same API costs as traditional approach
- Edge Function Execution: Included in Supabase subscription
Development Efficiency:
- Reduced Development Time: 60-80% faster AI feature implementation
- No Specialized AI Infrastructure Team: Use existing full-stack developers
- Unified Development Stack: Single platform for all backend needs
- Built-in Best Practices: Optimized AI patterns included
Total Monthly Cost for Supabase AI Startup: $300-$1,200/month + $200K-$300K annually in development talent
Annual Savings: $300K-$500K compared to traditional AI infrastructure approach
ROI Calculation Example
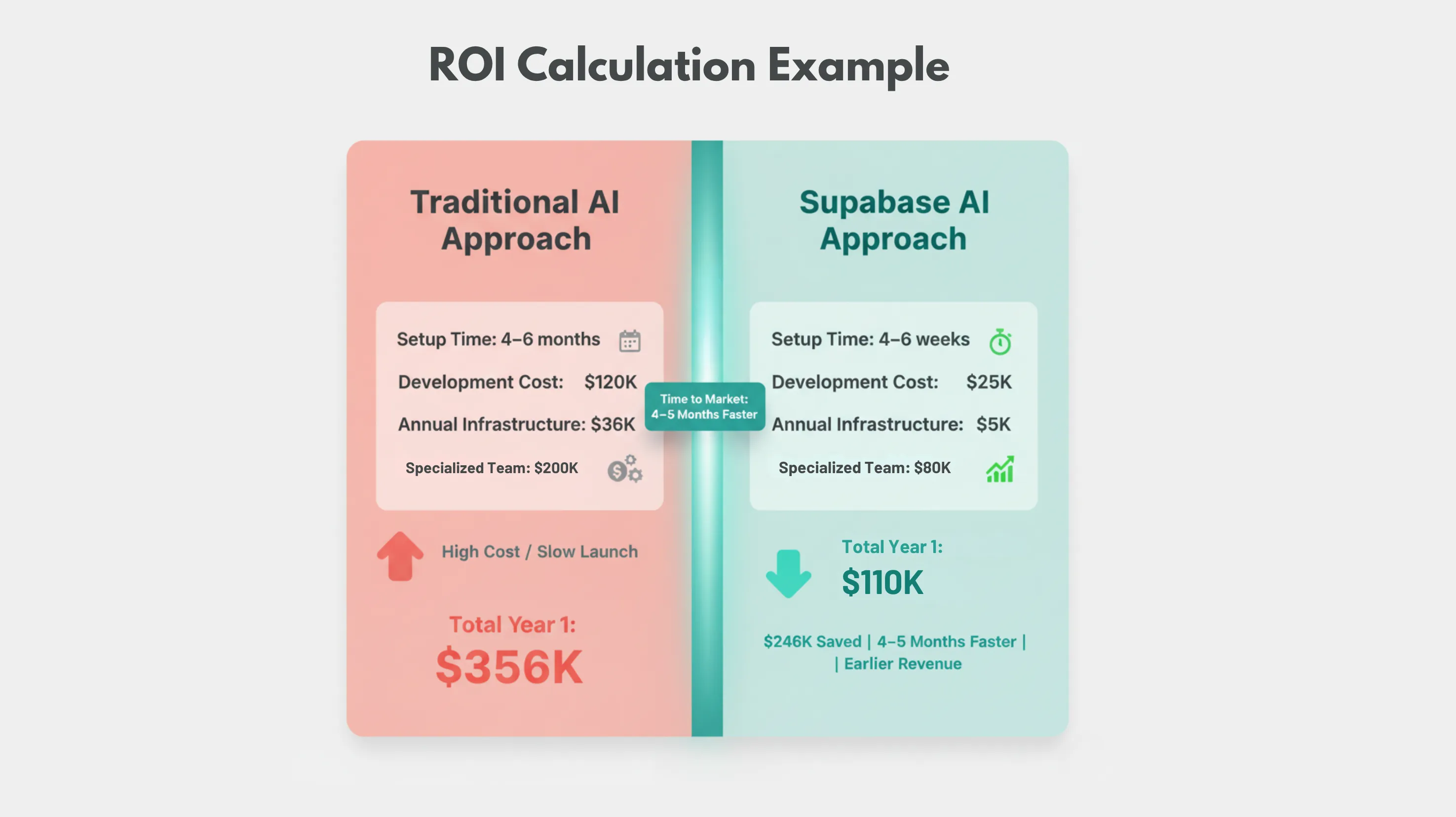
Scenario: E-commerce startup adding AI-powered product recommendations
| Traditional Approach | Supabase Approach |
|---|---|
| Setup Time: 4-6 months | Setup Time: 4-6 weeks |
| Development Cost: $120K | Development Cost: $25K |
| Annual Infrastructure: $36K | Annual Infrastructure: $5K |
| Specialized Team: $200K annually | Specialized Team: $80K additional |
| Total Year 1: $356K | Total Year 1: $110K |
Savings: $246K in first year (69% cost reduction) Time to Market: 4-5 months faster Revenue Impact, Earlier AI features generate revenue sooner
AI Implementation Patterns and Best Practices
1. RecommendationSystems
User-Based Collaborative Filtering:
-- Store user preference embeddings
CREATE TABLE user_preferences (
user_id BIGINT PRIMARY KEY,
preference_embedding VECTOR(1536),
last_updated TIMESTAMP DEFAULT now()
);
-- Find similar users for recommendations
CREATE OR REPLACE FUNCTION get_similar_users(target_user_id BIGINT)
RETURNS TABLE(similar_user_id BIGINT, similarity_score FLOAT) AS $$
BEGIN
RETURN QUERY
SELECT
up2.user_id AS similar_user_id,
1 - (up1.preference_embedding <=> up2.preference_embedding) AS similarity_score
FROM user_preferences up1, user_preferences up2
WHERE up1.user_id = get_similar_users.target_user_id
AND up2.user_id != get_similar_users.target_user_id
ORDER BY up1.preference_embedding <=> up2.preference_embedding
LIMIT 10;
END;
$$ LANGUAGE plpgsql;Content-Based Recommendations:
-- Recommend items similar to a user's past interactions
CREATE OR REPLACE FUNCTION content_based_recommendations(
target_user_id BIGINT
)
RETURNS TABLE(item_id BIGINT, recommendation_score FLOAT) AS $$
BEGIN
RETURN QUERY
WITH user_history AS (
SELECT DISTINCT item_id
FROM user_interactions
WHERE user_id = content_based_recommendations.target_user_id
AND interaction_type IN ('purchase', 'like', 'bookmark')
),
user_preference_vector AS (
SELECT AVG(i.item_embedding) AS avg_embedding
FROM items i
JOIN user_history uh ON i.id = uh.item_id
)
SELECT
i.id AS item_id,
1 - (i.item_embedding <=> upv.avg_embedding) AS recommendation_score
FROM items i, user_preference_vector upv
WHERE i.id NOT IN (SELECT item_id FROM user_history)
ORDER BY i.item_embedding <=> upv.avg_embedding
LIMIT 20;
END;
$$ LANGUAGE plpgsql;2.SemanticSearchand RAG (Retrieval-Augmented Generation)
Knowledge Base Search:
-- Store knowledge base with embeddings
CREATE TABLE knowledge_base (
id BIGINT PRIMARY KEY,
title TEXT,
content TEXT,
category TEXT,
content_embedding vector(1536),
created_at timestamp DEFAULT now(),
updated_at timestamp DEFAULT now()
);
-- Semantic search for RAG
CREATE OR REPLACE FUNCTION search_knowledge_base(
query_text TEXT,
category_filter TEXT DEFAULT NULL,
limit_results INT DEFAULT 5
)
RETURNS TABLE(
kb_id BIGINT,
title TEXT,
content TEXT,
relevance_score FLOAT
) AS $$
DECLARE
query_embedding vector(1536);
BEGIN
-- Get query embedding
SELECT embedding INTO query_embedding
FROM generate_embedding(query_text);
RETURN QUERY
SELECT
kb.id AS kb_id,
kb.title,
kb.content,
1 - (kb.content_embedding <=> query_embedding) AS relevance_score
FROM knowledge_base kb
WHERE category_filter IS NULL OR kb.category = category_filter
ORDER BY kb.content_embedding <=> query_embedding
LIMIT limit_results;
END;
$$ LANGUAGE plpgsql;Context Assembly for LLM:
-- Function to prepare context for LLM
CREATE OR REPLACE FUNCTION prepare_rag_context(
user_query TEXT,
max_context_length INT DEFAULT 3000
)
RETURNS JSONB AS $$
DECLARE
context_pieces TEXT[] := ARRAY[]::TEXT[];
final_context TEXT;
current_length INT := 0;
piece_record RECORD;
BEGIN
-- Get relevant knowledge pieces
FOR piece_record IN
SELECT content, relevance_score
FROM search_knowledge_base(user_query, NULL, 10)
ORDER BY relevance_score DESC
LOOP
-- Check if adding this piece would exceed context limit
IF current_length + length(piece_record.content) < max_context_length THEN
context_pieces := array_append(context_pieces, piece_record.content);
current_length := current_length + length(piece_record.content);
ELSE
EXIT; -- Stop adding pieces
END IF;
END LOOP;
-- Combine context pieces
final_context := array_to_string(context_pieces, E'
------
');
RETURN jsonb_build_object(
'query', user_query,
'context', final_context,
'context_length', current_length,
'pieces_used', COALESCE(array_length(context_pieces, 1), 0)
);
END;
$$ LANGUAGE plpgsql;3.Intelligent Content Classification
Multi-label Classification:
-- Store content with classification embeddings
CREATE TABLE content_classification (
content_id BIGINT PRIMARY KEY,
content_text TEXT,
content_embedding VECTOR(1536),
predicted_categories TEXT[],
confidence_scores FLOAT[],
human_verified BOOLEAN DEFAULT FALSE
);
-- Classify new content based on existing examples
CREATE OR REPLACE FUNCTION classify_content(
new_content TEXT
)
RETURNS TABLE(category TEXT, confidence FLOAT) AS $$
DECLARE
content_emb VECTOR(1536);
BEGIN
-- Generate embedding for new content
SELECT embedding INTO content_emb
FROM generate_embedding(new_content);
-- Find similar content and aggregate category predictions
RETURN QUERY
WITH similar_content AS (
SELECT
unnest(predicted_categories) AS category,
unnest(confidence_scores) AS confidence,
1 - (cc.content_embedding <=> content_emb) AS similarity
FROM content_classification cc
WHERE human_verified = TRUE
ORDER BY cc.content_embedding <=> content_emb
LIMIT 50
),
weighted_categories AS (
SELECT
category,
AVG(confidence * similarity) AS weighted_confidence,
COUNT(*) AS support_count
FROM similar_content
GROUP BY category
)
SELECT
wc.category,
wc.weighted_confidence
FROM weighted_categories wc
WHERE wc.support_count >= 3
ORDER BY wc.weighted_confidence DESC;
END;
$$ LANGUAGE plpgsql;Future-Proofing Your AI Strategy
1. Emerging AI Capabilities in Supabase
Multi-model Support:
- Text Embeddings: OpenAI, Cohere, Sentence Transformers
- Image Embeddings: CLIP, Vision Transformer models
- Audio Embeddings: Whisper, speech recognition models
- Video Embeddings: Video understanding and search capabilities
Advanced Vector Operations:
- Hybrid Search: Combine semantic and traditional search
- Clustering: Automatic content grouping and organization
- Anomaly Detection: Identify unusual patterns in data
- Recommendation Diversity: Balance relevance with discovery
AI Model Integration:
- Local Model Hosting: Run custom models on Supabase Edge Functions
- Model Versioning: A/B test different AI models
- Performance Optimization: Automatically optimize for speed and cost
- Compliance Tools: Built-in AI governance and audit trails
2. Scaling AI with Business Growth
Performance Optimization:
- Index Tuning: Optimize vector indexes for your specific use case
- Query Optimization: Efficient similarity search patterns
- Caching Strategies: Cache frequent AI operations
- Batch Processing: Handle large-scale AI operations efficiently
Cost Management:
- Embedding Caching: Avoid regenerating identical embeddings
- Smart Model Selection: Use appropriate models for different tasks
- Usage Monitoring: Track AI costs and optimize spending
- Tiered AI Features: Offer different AI capabilities by user tier
Organizational Scaling:
- AI Governance: Policies for responsible AI development
- Team Training: Upskill developers on AI implementation
- Quality Assurance: Testing and validation of AI features
- User Education: Help users understand and adopt AI features
Getting Started: Your AI Implementation Roadmap
Phase 1: FoundationSetup(Week 1-2)
AI Strategy Planning:
- Identify Use Cases: Which AI features will provide the most user value?
- Evaluate Data: What data do you have available for AI features?
- Set Success Metrics: How will you measure AI feature success?
- Plan Integration: How will AI features fit into existing workflows?
Technical Preparation:
- Enable pgvector: Add vector support to your Supabase project
- Set up Edge Functions: Prepare AI processing infrastructure
- Configure API Keys: Set up connections to AI services (OpenAI, etc.)
- Design Data Schema: Plan how to store embeddings with existing data
Phase2: MVPImplementation (Week3-6)
Start with One Use Case:
- Choose Simple Feature: Begin with search, recommendations, or classification
- Implement Basic Version: Get working AI feature with minimal complexity
- Test with Real Data: Use actual user data to validate approach
- Measure Performance: Track both technical and business metrics
Common Starting Points:
-- Simple semantic search implementation
CREATE TABLE searchable_content (
id BIGINT PRIMARY KEY,
title TEXT,
content TEXT,
content_embedding VECTOR(1536),
created_at TIMESTAMP DEFAULT now()
);
-- Basic search function
CREATE OR REPLACE FUNCTION semantic_search_basic(query_text TEXT)
RETURNS TABLE(content_id BIGINT, title TEXT, relevance FLOAT) AS $$
DECLARE
query_embedding VECTOR(1536);
BEGIN
-- Generate embedding for search query
SELECT embedding INTO query_embedding
FROM generate_embedding(query_text);
RETURN QUERY
SELECT
sc.id,
sc.title,
1 - (sc.content_embedding <=> query_embedding) AS relevance
FROM searchable_content sc
ORDER BY sc.content_embedding <=> query_embedding
LIMIT 10;
END;
$$ LANGUAGE plpgsql;Phase3: Enhancement and Optimization (Week 7-10)
Improve Performance:
- Add Indexes: Optimize vector search performance
- Implement Caching: Cache frequent embeddings and results
- Optimize Queries: Improve complex AI query performance
- Monitor Usage: Track AI feature adoption and performance
Enhance User Experience:
- Add Filters: Combine AI with traditional filtering
- Improve Relevance: Fine-tune similarity thresholds
- Add Explanations: Help users understand AI recommendations
- Implement Feedback: Learn from user interactions
Phase 4: AdvancedFeatures (Week 11+)
Multi-modal AI:
- Image Search: Add visual similarity search
- Content Classification: Automatic categorization
- Recommendation Diversity: Balance relevance with discovery
- Personalization: User-specific AI behavior
AI Analytics:
- Performance Tracking: Monitor AI feature effectiveness
- Cost Analysis: Track and optimize AI-related expenses
- User Behavior: Understand how users interact with AI features
- Business Impact: Measure AI contribution to key metrics
Choosing the Right AI Development Partner
1. Essential AI Development Capabilities
Supabase AI Expertise:
- Vector Database Proficiency: Deep understanding of pgvector capabilities
- Embedding Strategy: Knowledge of different embedding models and use cases
- Performance Optimization: Experience optimizing AI queries and indexes
- AI API Integration: Expertise with OpenAI, Cohere, and other AI services
Business AI Understanding:
- Use Case Identification: Ability to identify valuable AI applications
- ROI Measurement: Track and optimize AI feature business impact
- User Experience Design: Create intuitive AI-powered interfaces
- Ethical AI Practices: Implement responsible AI development practices
Technical Integration Skills:
- Full-stack Development: Integrate AI backend with frontend interfaces
- Real-time Implementation: Build responsive AI features
- Scaling Expertise: Design AI systems that grow with your business
- Monitoring and Analytics: Implement comprehensive AI observability
2. Evaluating AI DevelopmentTeams
Portfolio Assessment:
- AI Project Examples: Real applications using Supabase for AI features
- Performance Metrics: Demonstrated improvement in user engagement
- Scaling Success: Projects that grew from MVP to production scale
- Industry Relevance: Experience in your specific business domain
Technical Evaluation:
-- Ask candidates to explain this query and its optimization opportunities
EXPLAIN (ANALYZE, BUFFERS)
SELECT
content_id,
title,
1 - (embedding <=> $1) AS similarity
FROM content_embeddings
WHERE category = $2
ORDER BY embedding <=> $1
LIMIT 20;
Communication and Collaboration:
- AI Explanation Skills: Can explain AI concepts in business terms
- Strategic Thinking: Understands AI's role in business strategy
- Iterative Approach: Willing to start simple and enhance over time
- Measurement Focus: Emphasizes tracking and optimizing AI impact
Your AI-Powered Future Starts Today
The AI revolution is happening now, and Supabase gives you the tools to participate without the traditional barriers of complexity and cost.
The opportunity is massive: AI can transform user experience, automate complex tasks, and create entirely new product categories.
The implementation is finally simple: With Supabase, adding sophisticated AI features is as straightforward as adding user authentication or file storage.
The time is now : While competitors struggle with complex AI infrastructure, you can ship intelligent features that delight users and drive growth.
Ready to Build AI-Powered Applications?
At Gaincafe, we specialize in helping startups implement AI features quickly and cost-effectively using Supabase. Our team has deep expertise in both Supabase and AI, enabling us to deliver intelligent applications that provide real business value.
Our AI development services include:
- AI Strategy Consulting: Identify the most valuable AI use cases for your business
- Rapid AI Prototyping: Validate AI concepts quickly and cost-effectively
- Production AI Implementation: Build scalable, robust AI features
- Performance Optimization: Ensure AI features are fast and cost-efficient
- Ongoing AI Enhancement: Continuously improve AI capabilities based on user feedback
Schedule a free AI consultation to discuss your AI vision and discover how Supabase can make it reality.
Contact us today to start building AI features that give you a competitive advantage.
Remember: The best time to add AI to your product was yesterday. The second best time is today, with Supabase making it simpler than ever.**
